Meta 提出“Active Reading”框架,让大模型像人一样“精读”
meta fair 与加州大学伯克利分校今日联合推出全新研究成果——active reading 框架,首次将“主动学习”理念引入大模型训练流程。该框架让模型在阅读指定材料时,自主生成个性化的学习策略,从而实现知识的高效、深度吸收,尤其适用于大规模训练场景。

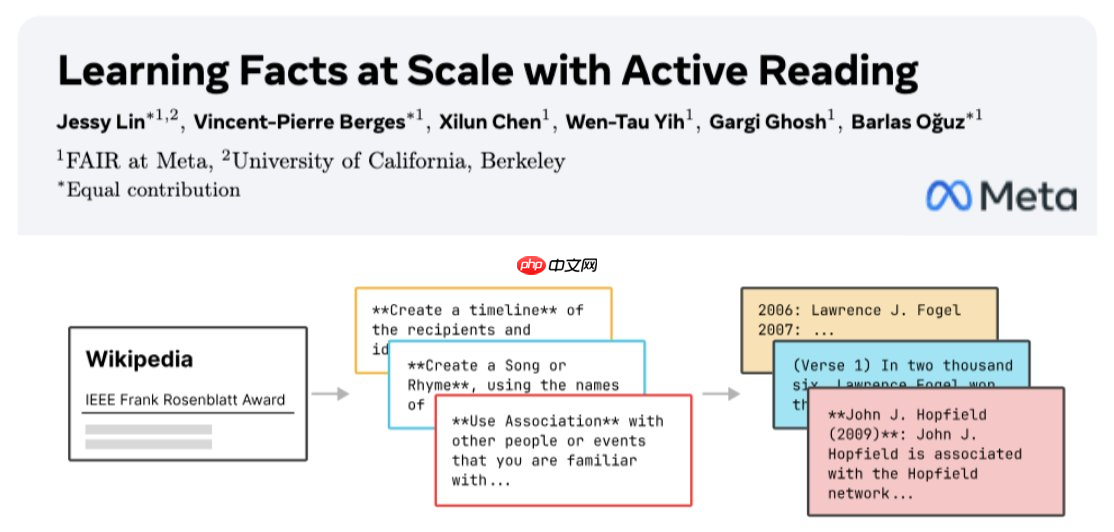
具体而言,当模型接收到一篇文档时,会先自行规划“学习方法”,例如生成摘要、构建联想、设计自测题目等;随后利用这些策略自动生成大量高质量的训练样本,真正做到对文本内容的“深度消化”。
https://www.php.cn/link/9ef76737dc71b2cf44533b32fb344419
实测表现令人瞩目:
- 在金融专业评测集 FinanceBench 上,准确率从 16% 提升至 26%,相对增幅达 160%。
- 面向长尾知识的 SimpleQA 基准中,准确率由 16% 跃升至 66%,提升幅度高达 312%。
- 利用该框架生成的 1T tokens 数据训练出的 8B 参数模型 Meta WikiExpert,在事实性问答任务中表现超越 Llama 3.1(405B)与 DeepSeekV2(236B)等超大规模模型。
核心优势包括:
- 全流程自动化:无需人工干预或设计问答模板,完全由模型自主完成学习路径构建。
- 数据形式丰富:单篇文档可生成释义、类比、填空题、多轮对话问答等多种训练样本。
- 高度可扩展:已在预训练阶段验证其可扩展至万亿 token 级别,具备工业级应用潜力。
研究团队下一步将探索 Active Reading 与检索增强生成(RAG)的融合,打造“边读边查”的新型学习范式。论文已发布于 arXiv,相关代码与数据集也将陆续开源。
网友留言(0 条)