Jina-VLM:可在笔记本上跑的多语言视觉小模型
ai 搜索公司 jina ai 正式推出全新视觉语言大模型 jina-vlm,该模型拥有 24 亿参数,是当前开源领域中规模达 20 亿级的 vlm 中,在多语言视觉问答任务上表现最为领先的模型。

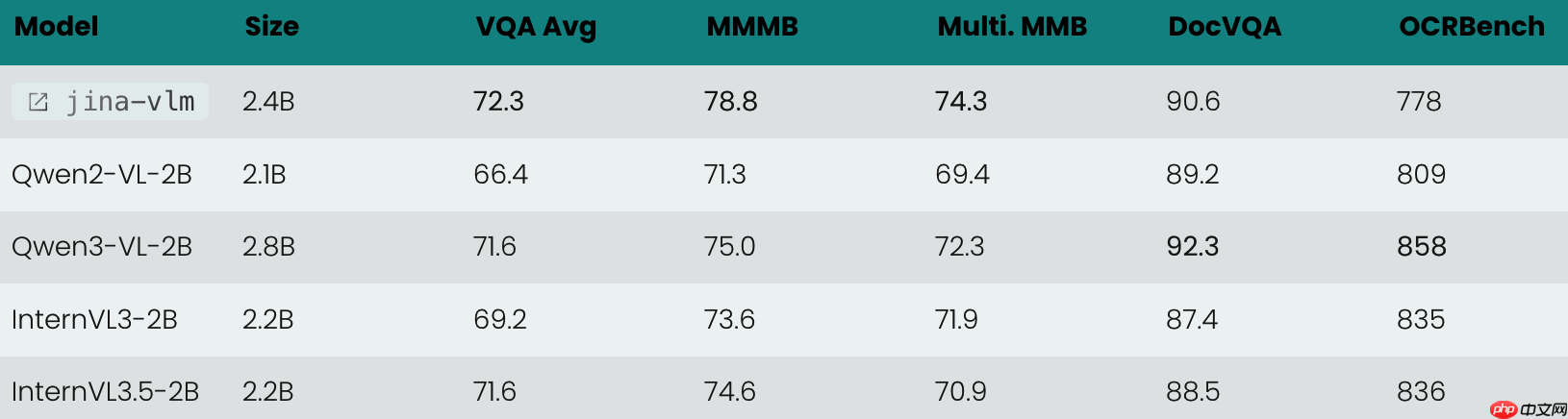
Jina-VLM 创新性地融合了 SigLIP2 视觉编码器与 Qwen3 语言主干网络,并通过注意力池化连接器(Attention Pooling Connector)实现高效跨模态对齐。这一设计使其在覆盖 29 种语言的多语言场景下均展现出强大性能,同时兼顾推理速度与资源占用。其整体架构如图所示,清晰呈现了“SigLIP2 视觉编码器 → VL-Connector → Qwen3 语言基座”的信息流向。
得益于轻量化的结构设计与优化策略,Jina-VLM 对硬件要求极低,可在主流消费级 GPU 或 Apple M 系列芯片的 MacBook 上稳定、流畅运行。
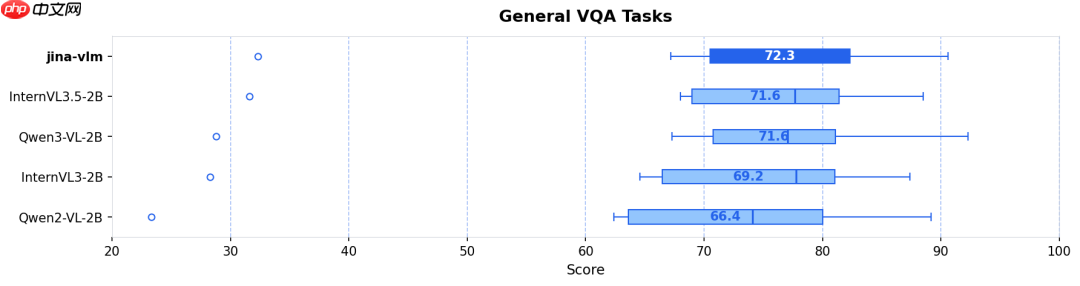
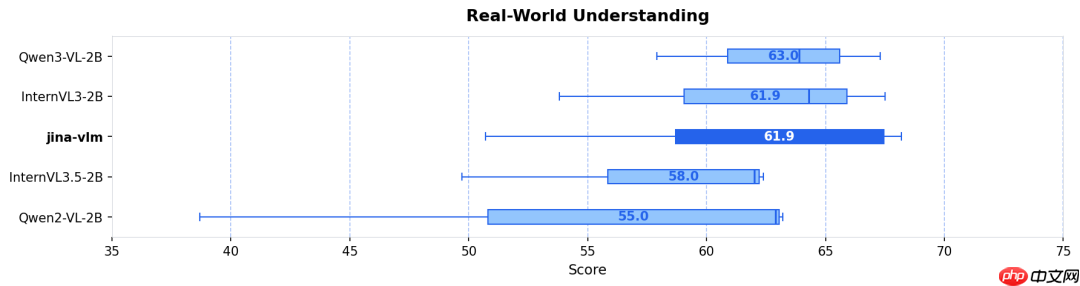
实测结果显示:无论是在标准视觉问答(VQA)、多语言多模态理解(MMMB、MMBench),还是 OCR 解析与纯文本推理(如常识问答、数学推理)等多样化任务中,Jina-VLM 均达到同参数量级模型中的顶尖水平,并同步实现了面向消费级设备的高度友好型推理效率。
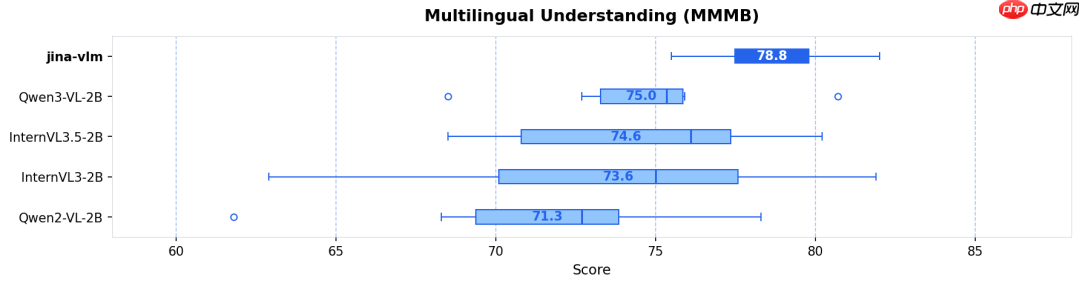
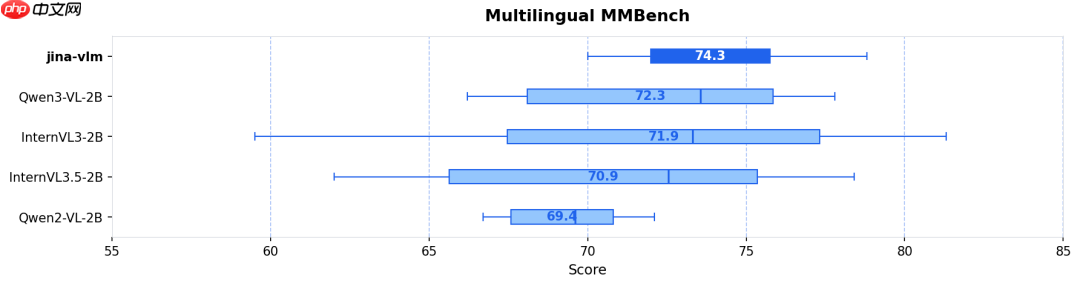
- 多语言多模态理解(MMMB SOTA):在阿拉伯语、中文、英语、葡萄牙语、俄语及土耳其语六大语种组成的 MMMB 基准测试中,Jina-VLM 以 78.8 分的综合得分位居榜首,充分验证其卓越的跨语言视觉语义理解能力(参见图 1 & 图 2)。
- 高难度视觉问答(VQA):在 ChartQA(图表理解)、DocVQA(文档问答)、TextVQA(场景文字识别问答)以及 CharXiv(科学图表解析)等多项极具挑战性的评测中,模型均保持稳健且精准的表现(参见图 3)。
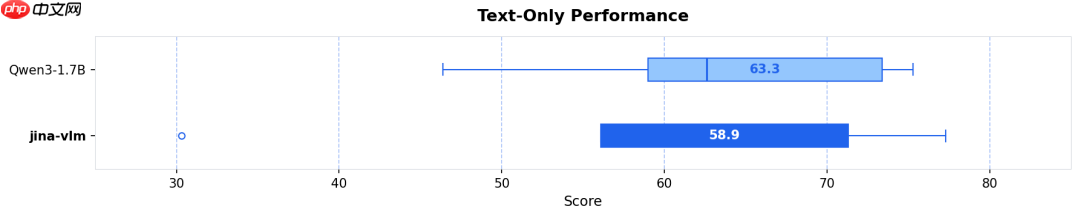
- 视觉增强不损语言能力:多数视觉语言模型在强化图像理解能力时往往导致文本能力下降。而 Jina-VLM 凭借独特的训练范式,在 MMLU(大规模多任务语言理解)和 GSM-8K(小学数学应用题)等纯文本基准上,几乎完整继承了 Qwen3 原始基座的强大语言能力(参见图 5)。
论文地址:https://www.php.cn/link/3a532033aa5b0c64d1a7b2b13e4b5d33
Hugging Face 模型页:https://www.php.cn/link/76daf89ce28106580694a0eea18a27ee
源码获取:点击下载
下一篇 >>
网友留言(0 条)