字节 Seed 发布 GR-RL,首次实现真机强化学习穿鞋带
字节跳动 seed 团队近日公布了其在视觉-语言-动作(vla)模型领域的最新进展——gr-rl,该研究致力于突破机器人在长时程、高精度灵巧操作任务中的能力极限。


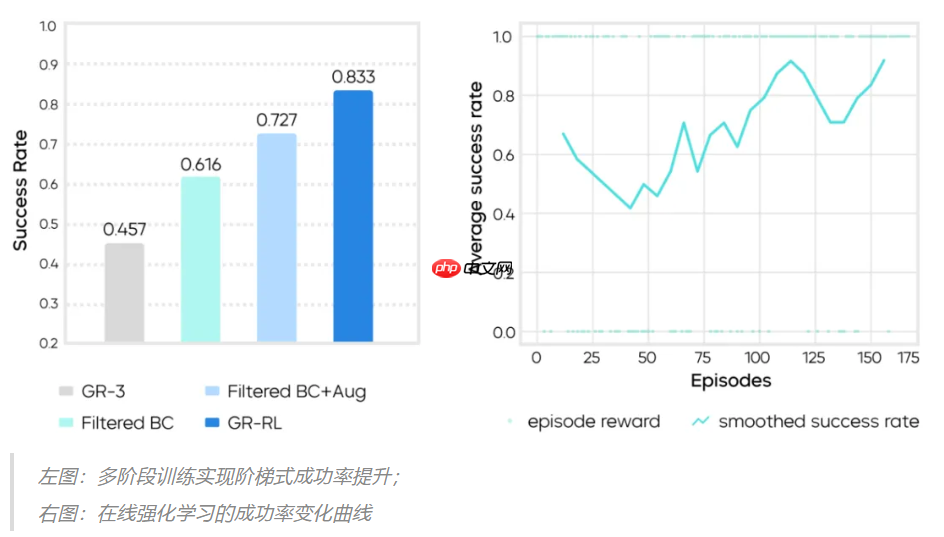
GR-RL 构建了一个融合离线数据筛选与在线真实环境微调的强化学习框架,在业内首次实现了“机器人自主为整只鞋连续穿入鞋带”的复杂操作。相比此前基于监督学习的 GR-3 模型,GR-RL 将任务成功率从 45.7% 显著提升至 83.3%,失败率降低近 70%。
据技术介绍,GR-RL 在原有 VLA 架构基础上引入了一个额外的判别器网络(Critic Transformer),用于评估机器人每一步动作的质量,并对整个动作序列中的每个时间步进行打分。具体实现中,采用了值分布强化学习方法,将判别器的输出建模为离散概率分布,从而更有效地应对现实环境中存在的各类噪声干扰。
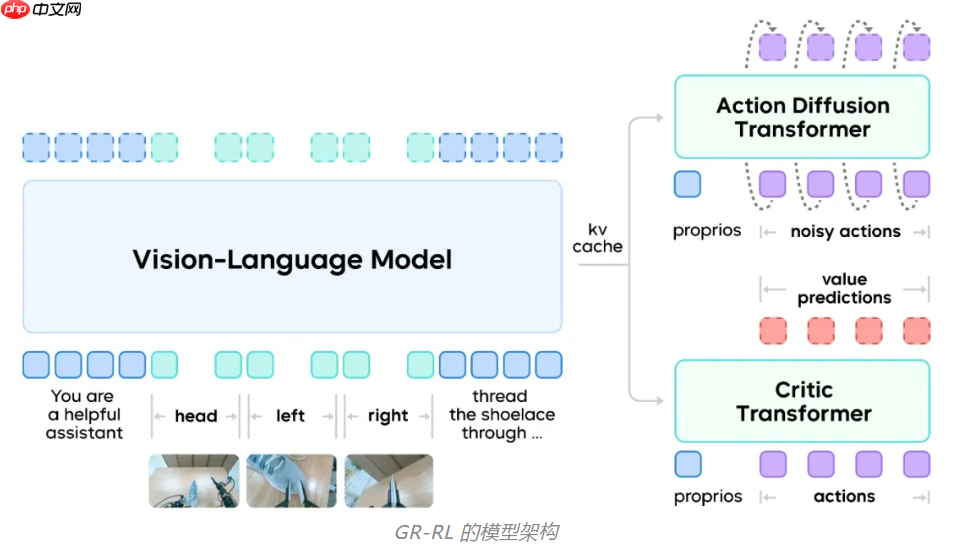
依托这一结构,GR-RL 设计了一套“从经验中学习、在实践中进化”的多阶段训练流程,包含三大核心模块:离线强化学习、数据增强和在线强化学习。
实验在双臂轮式机器人平台 ByteMini-v2 上展开,以“穿鞋带”作为典型精细操作任务进行全面验证。该机器人具备独特的球形腕关节设计,可实现类似人类手腕的自由旋转,在执行高精度操作时展现出显著优势。
测试结果显示,仅依赖模仿学习的基线模型 GR-3 成功率仅为 45.7%,难以完成复杂穿引任务。而 GR-RL 通过阶段性优化逐步提升性能,各模块均发挥关键作用:
- 数据过滤:去除低质量轨迹后,离线阶段的成功率提升至 61.6%;
- 数据增强:通过镜像翻转等方式扩充数据集,使成功率进一步提高到 72.7%;
- 在线强化学习:以增强后的模型为起点,在真实机器人上进行约 150 条轨迹的闭环探索与策略修正,最终 GR-RL 的成功率达到了 83.3%。
源码地址:点击下载
<< 上一篇
下一篇 >>
网友留言(0 条)