巨人网络发布三大 Muli-Modal 模型
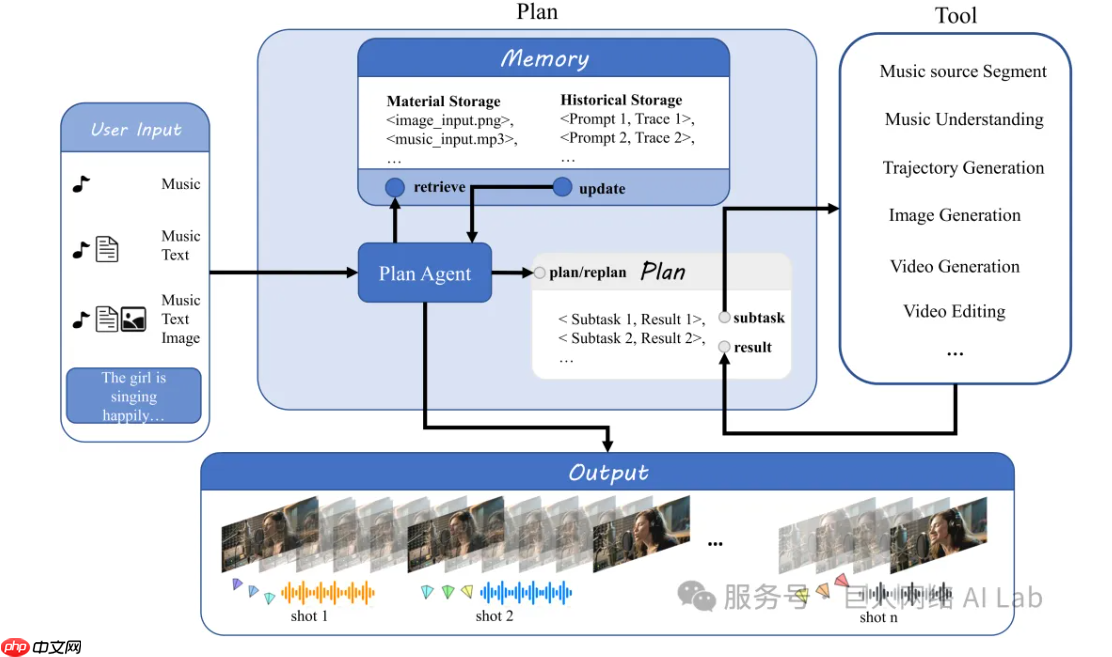

巨人网络AI Lab携手清华大学SATLab及西北工业大学,共同发布了三项音视频多模态生成技术成果——YingVideo-MV、YingMusic-SVC与YingMusic-Singer,并宣布相关研究将逐步在GitHub、HuggingFace等平台开源。
此次推出的YingVideo-MV模型,仅需一段音乐和一张人物图像,便可自动生成节奏协调、画面流畅的音乐视频片段。该模型通过对音乐的节奏、情绪和结构进行深度解析,实现镜头运动与音频的高度匹配,支持推、拉、摇、移等多种专业级运镜效果,并引入长时序一致性机制,显著减少了长时间生成中常见的人物形变与画面跳帧问题。
在音频领域,YingMusic-SVC具备“真实歌曲可用”的零样本歌声转换能力。经过对真实音乐环境的全面优化,该模型能有效过滤伴奏、和声与混响带来的干扰,大幅降低破音和高音失真现象,为音乐翻唱、风格迁移等创作提供了高质量、高稳定性的技术支持。
另一项音频成果YingMusic-Singer则专注于歌声合成,用户只需提供旋律与歌词,即可生成自然流畅、音准稳定的演唱音频。该模型支持任意长度歌词输入,并具备零样本音色克隆功能,无需大量训练数据即可复现目标音色,极大增强了AI在音乐创作中的实用性与灵活性,进一步降低了创作门槛。
源码地址:点击下载
网友留言(0 条)