银河通用发布环视导航基座大模型 NavFoM
银河通用携手北京大学、阿德莱德大学、浙江大学等科研团队,共同发布了全球首个实现跨本体全域环视的导航基座大模型——navfom(navigation foundation model),首次将视觉-语言导航(vision-and-language navigation)、目标导向导航(object-goal navigation)、视觉跟踪(visual tracking)以及自动驾驶(autonomous driving)等多种机器人导航任务统一于同一框架之下。

- 全场景覆盖:模型兼容室内与室外环境,支持在未见过的新场景中实现Zero-Shot推理,无需预先建图或额外采集训练数据即可运行;
- 多任务融合:可响应自然语言指令,完成诸如目标跟随、自主路径规划等多样化导航子任务;
- 跨本体适配:能够快速、低成本地部署至机器狗、轮式人形机器人、腿式人形机器人、无人机乃至汽车等多种形态和尺寸的异构载体。
更进一步,NavFoM 可作为通用基座,供开发者通过后续微调或后训练,演化为满足特定应用场景需求的专业化导航模型。
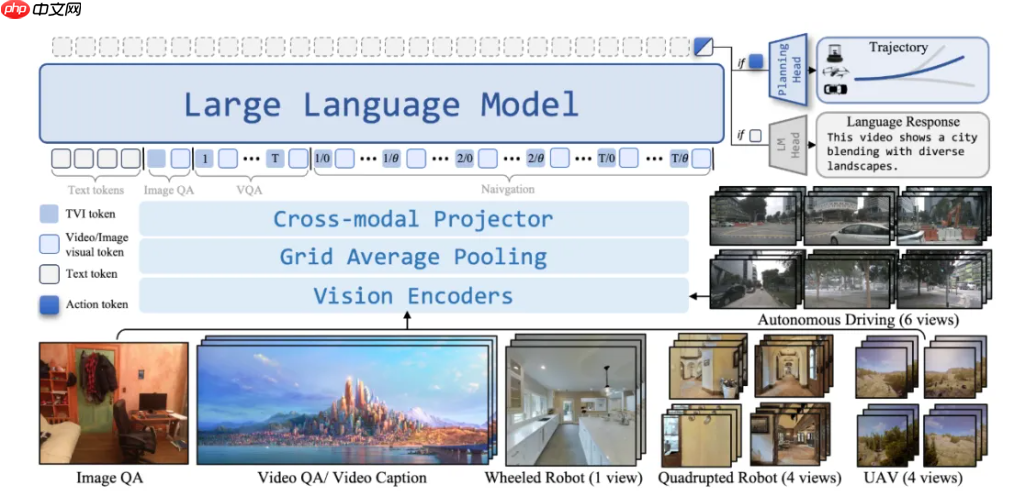
NavFoM 提出了一个全新的通用范式:“视频流 + 文本指令 → 动作轨迹”。无论是“请跟着前方行人”还是“去找到门口那辆红色汽车”,所有任务均以一致的输入输出形式处理。该模型摆脱了传统模块化系统的拼接结构,实现了从感知到理解再到决策执行的端到端闭环。
这一突破意味着原本相互孤立的导航任务可通过统一的数据对齐与任务建模实现知识迁移,不同形态的机器人亦能共享视觉认知与运动控制的经验。
NavFoM 的核心技术包含两项创新:
- TVI Tokens(Temporal-Viewpoint-Indexed Tokens)——赋予模型对时间序列与空间视角变化的深层理解能力;
- BATS 策略(Budget-Aware Token Sampling)——在计算资源受限的情况下,智能选择关键信息token,确保高效且精准的推理表现。
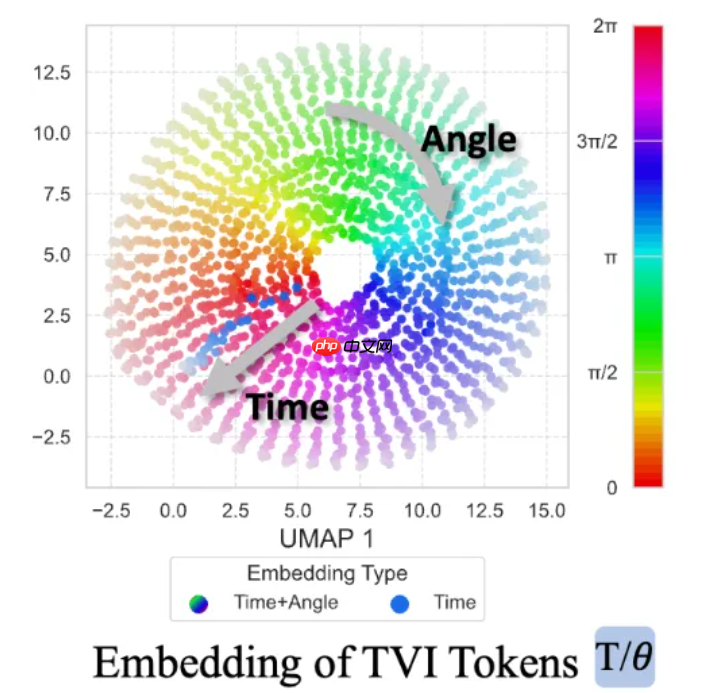
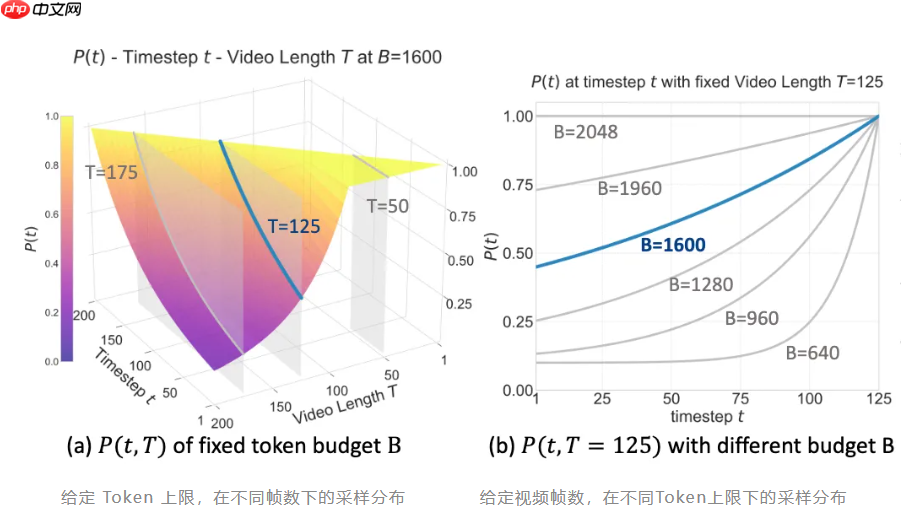
为支撑该模型的训练,银河通用构建了迄今规模最大的跨任务导航数据集,包含高达八百万条涵盖视觉语言导航、目标导航、视觉跟踪、自动驾驶及网络导航等多类型任务的跨本体数据,并融合四百万条开放域问答样本,强化模型在语言与空间语义之间的关联理解能力。整体训练数据量约为此前同类研究的两倍水平。
网友留言(0 条)