新加坡科技巨头 Grab 近期在其工程博客披露了自主研发视觉语言模型的技术路径,指出当前主流大型语言模型在应对东南亚地区多样的本地语言时存在明显短板。作为一款集打车、外卖配送、在线购物与数字金融服务于一体的超级应用,Grab 的业务遍及新加坡、马来西亚、印度尼西亚、菲律宾、越南、泰国、柬埔寨和缅甸等多个国家。这些区域广泛使用非拉丁字母的文字系统,为文本识别带来了巨大挑战。
在诸如用户身份核验等关键合规流程中,Grab 必须精准提取身份证件、驾驶执照及企业注册文件中的...
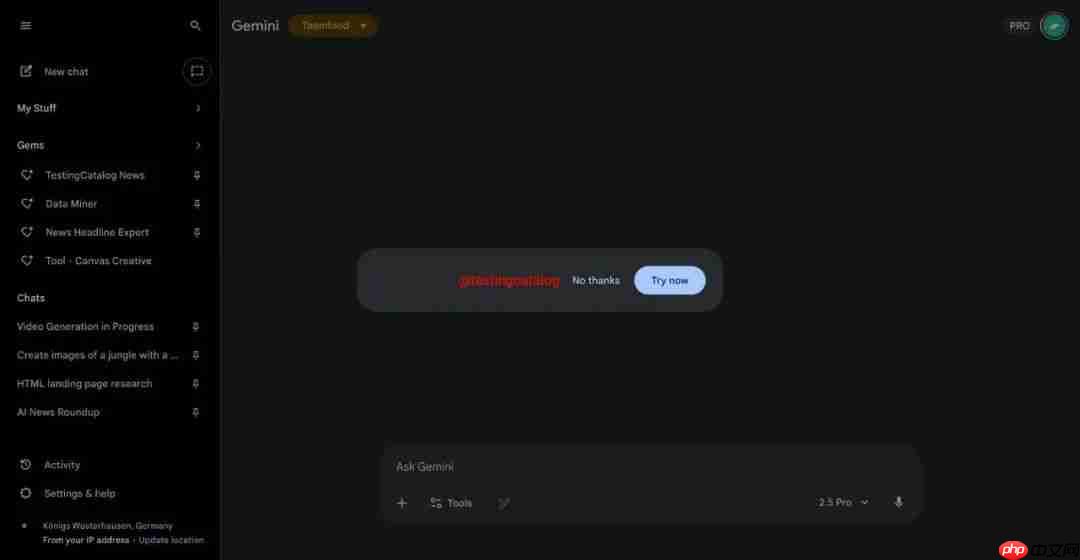
根据 TestingCatalog 的最新消息,Google Gemini 网页端近日出现了一张新的功能预告卡片。
该信息显示,谷歌正计划推出其下一代图像生成模型,属于 Nano Banana 系列的升级版本。新模型或将命名为“GEMPIX2”,作为 Nano Banana 的第二代产品亮相。
报道指出,此类预告卡片通常在功能正式上线前一周左右出现,因此推测 GEMPIX2 很可能将在下周正式发布。
此前发布的 Nano Banana(即 Gemini 2.5...
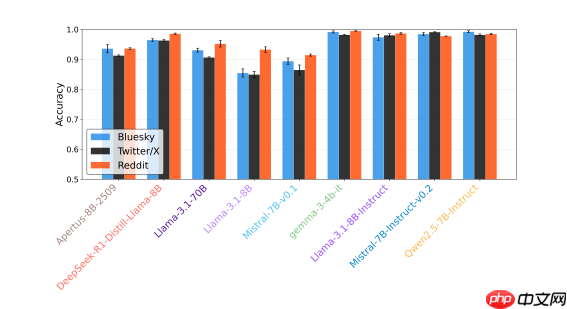
苏黎世大学、阿姆斯特丹大学、杜克大学以及纽约大学的联合研究团队近期公布了一项关于大语言模型在社交媒体内容生成方面表现的研究成果。研究发现,当前AI生成的社交平台帖子普遍存在可识别性问题,人类用户能够以高达70%至80%的准确率将其与真人发布的内容区分开来,显著高于随机判断的概率。
该研究涵盖了九个主流大语言模型,包括Apertus、DeepSeek、Gemma、Llama、Mistral和Qwen等,评估它们在Bluesky、Reddit和X三大社交平台上的文本生成...
商汤近日正式推出并开源了 sensenova-si 系列空间智能大模型,据官方披露,在多项权威评测的空间理解与推理任务中,该系列模型不仅显著超越同规模的开源多模态大模型,更在性能上优于 gpt-5 和 gemini 2.5 pro 等国际领先的闭源模型。
SenseNova-SI 定位于专注空间智能的大模型,此次开源涵盖 2B 和 8B 两个参数量版本。最新测评结果显示,该系列在多个空间智能基准测试(VSI、MMSI、MindCube、ViewSpatial)中表现优异...
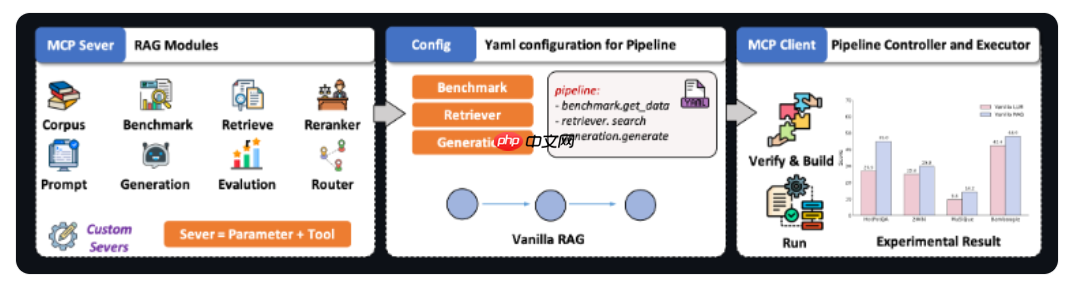
由清华大学THUNLP实验室、东北大学NEUIR实验室联合OpenBMB与AI9Stars共同推出的 UltraRAG2.1 正式上线,标志着全球首个基于Model Context Protocol(MCP)架构的开源RAG框架诞生。该版本极大简化了多模态智能检索系统的搭建过程——开发者仅需编写数行YAML配置,无需编写任何代码,即可完成从数据接入到推理生成再到效果评估的全流程部署,显著降低技术门槛。
UltraRAG2.1 集成了检索(Retriever)、生成(...
谷歌公司前首席执行官埃里克·施密特(eric schmidt)近日表示,他担心由于成本因素,全球大多数国家最终可能会选择使用中国的ai模型,而非西方的模型。
开源免费 vs. 闭源收费:地缘政治的新博弈
施密特在播客节目中指出,这背后存在一个关键的地缘政治问题。“美国最顶尖的AI模型是闭源的,而中国最顶尖的模型是开源的。开源意味着免费,而闭源模型则需要付费。”他认为,对于那些不像西方国家那样资金雄厚的政府和国家而言,他们最终很可能会选择以中国的模型为标准,这并非因为...
东北大学“小牛翻译”团队近期推出了以中文和英文为双核心的多语言翻译模型 lmt(large-scale multilingual translation)。该模型支持60种语言、234个翻译方向,涵盖英↔59种语言及中↔58种语言的互译,覆盖全球主要语系与广泛使用的语言。
支持的语言分类如下:
**语言资源**
**语言列表**
高资源13种
阿拉伯语(ar)、英语(en)、西班牙语(es)、德语(de)、法语(fr)、意大利语(it)、日语(ja)、荷...
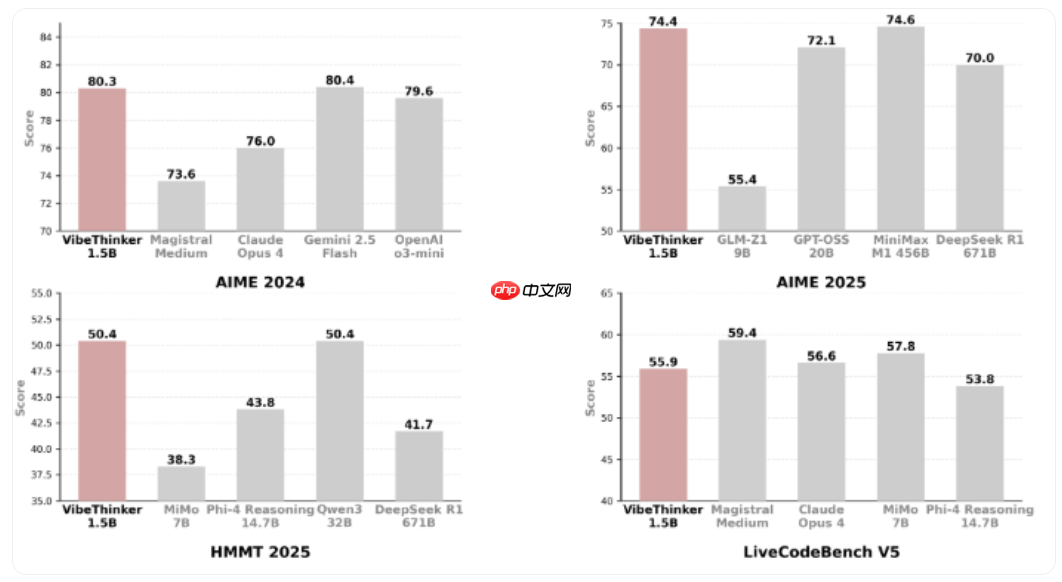
微博人工智能实验室近日发布了其开源的大型语言模型 VibeThinker-1.5B,该模型拥有15亿参数,是在阿里巴巴 Qwen2.5-Math-1.5B 的基础上经过精细调优而来。
尽管参数量仅为15亿,VibeThinker-1.5B 在数学推理与代码生成任务中展现出卓越能力,推理表现达到业界领先水平,甚至在多项评测中超越了参数高达6710亿的 DeepSeek R1 模型。此外,它还能与 Mistral AI 的 Magistral Medium、Anthro...
据《科创板日报》报道,阿里巴巴已秘密启动“千问”项目,基于 Qwen 最强模型打造一款同名个人 AI 助手 —— 千问 App,全面对标ChatGPT,加入全球 AI 应用的顶级竞赛。阿里核心管理层将其视为“AI 时代的未来之战”,希望借助 Qwen 的开源技术优势赢得竞争。
报道称,这是年初公布 3800 亿投入 AI 基础设施之后,阿里 AI 战略的又一重要布局。此前,阿里重兵一直放在 B 端 AI 市场,通过阿里云向各行各业提供模型 API 服务。基于 Qwen...
Databricks联合创始人Andy Konwinski在近期举行的Cerebral Valley AI峰会上发出警示:美国正在逐渐丧失其在AI研究领域的领先地位,而中国正迅速填补这一空白。他指出,这种转变已不仅仅是技术竞争问题,更是对民主体制的“生存性威胁”。
Konwinski引用来自伯克利和斯坦福大学博士生的观察称,过去一年中具有重要影响力的AI创新思路,大约有一半来自中国研究团队,这一比例远超以往任何时期。
他与前NEA合伙人Pete Sonsini、A...