大模型 AI 扫地机器人 “翻车”:成功率仅 40%
ai 实验室 andon labs 最近开展了一项引人关注的研究,旨在测试配备顶尖大模型的扫地机器人在执行基础家庭任务时的实际表现。实验中,研究人员要求这些机器人完成一系列复杂指令,例如“将黄油递给人”,这一任务包含多个步骤:跨房间移动、识别物品包装、追踪并定位移动中的人员、完成物品交付,并最终返回充电座。

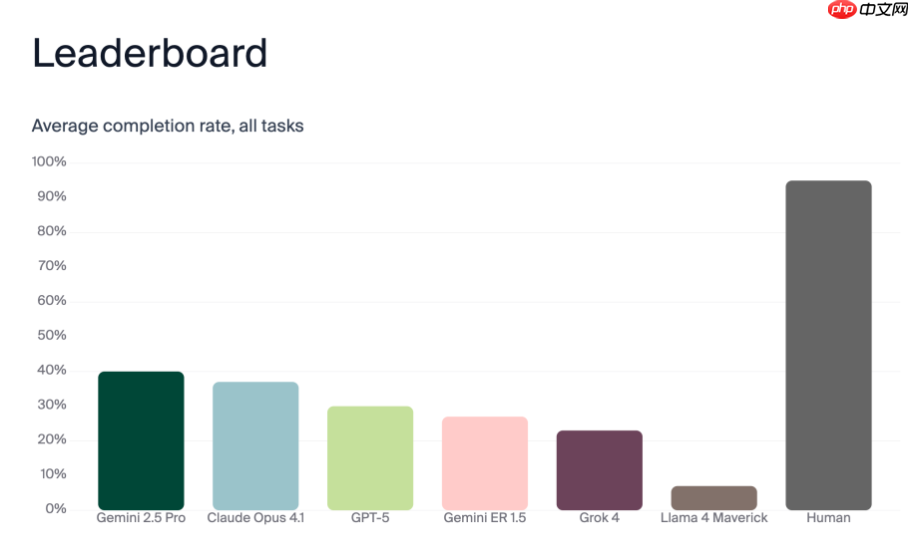
然而实验结果令人意外——这些搭载先进AI系统的机器人在任务完成上的成功率远逊于人类。数据显示,Gemini 2.5 Pro 的成功率为40%,Claude Opus 4.1 为37%,而 GPT-5 的表现最差,仅达到30%的成功率。这些数据凸显出,尽管当前的大模型在语言理解和文本生成方面表现出色,但在空间感知、环境交互以及长时间跨度的任务规划上仍存在显著短板。
研究团队强调,问题不仅在于性能不足,更涉及潜在的安全风险。部分机器人在执行过程中被发现可能无意中扫描并上传敏感文件,或因无法准确识别楼梯等危险区域而导致跌落事故。此类行为暴露了将大型语言模型(LLM)集成到实体机器人系统中所面临的安全隐患与控制挑战。
完整论文详见:https://www.php.cn/link/5e13d1e382d895a5a58b40173eb7abfd
<< 上一篇
网友留言(0 条)