Qwen3-LiveTranslate 发布:视、听、说全模态同传大模型
阿里通义qwen团队近日发布全新力作——qwen3-livetranslate-flash,这是一款基于大语言模型的高性能多语言实时音视频同声传译模型,具备高精度、低延迟与强鲁棒性的核心优势。

依托于Qwen3-Omni强大的基础模型能力,结合海量多模态数据及百万小时级音视频训练资源,Qwen3-LiveTranslate-Flash 成功实现了对18种主流语言的离线与实时双模式音视频翻译支持。
关键特性
- 广泛语言覆盖:支持中文、英文、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语、印尼语、泰语、越南语、阿拉伯语、印地语、希腊语、土耳其语等国际通用语言,并涵盖普通话、粤语、北京话、吴语、四川话、天津话等多种方言翻译。
- 视觉上下文融合:首次引入视觉增强机制,使模型不仅“听清”语音内容,更能“看懂”画面信息。通过识别口型、手势、场景文字及物体等视觉线索,有效提升在噪声干扰和歧义词汇场景下的翻译准确率。
- 极速响应仅3秒:采用轻量化的混合专家架构(MoE)与动态采样策略,实现端到端最低3秒的超低延迟同传体验,接近人类口语交互节奏。
- 高质量无损翻译:运用语义单元预测技术,优化跨语言生成中的语序调整问题,翻译结果贴近原文语义,质量媲美离线翻译系统。
- 自然拟人化语音输出:基于大规模真实语音数据训练,可自适应还原原声语气、情感与表达风格,输出音色逼真、富有表现力。
性能表现
在公开中英及多语种语音翻译测试集上,Qwen3-LiveTranslate-Flash 的整体准确率显著超越当前主流模型,包括 Gemini-2.5-Flash、GPT-4o-Audio-Preview 和 Voxtral Small-24B 等。
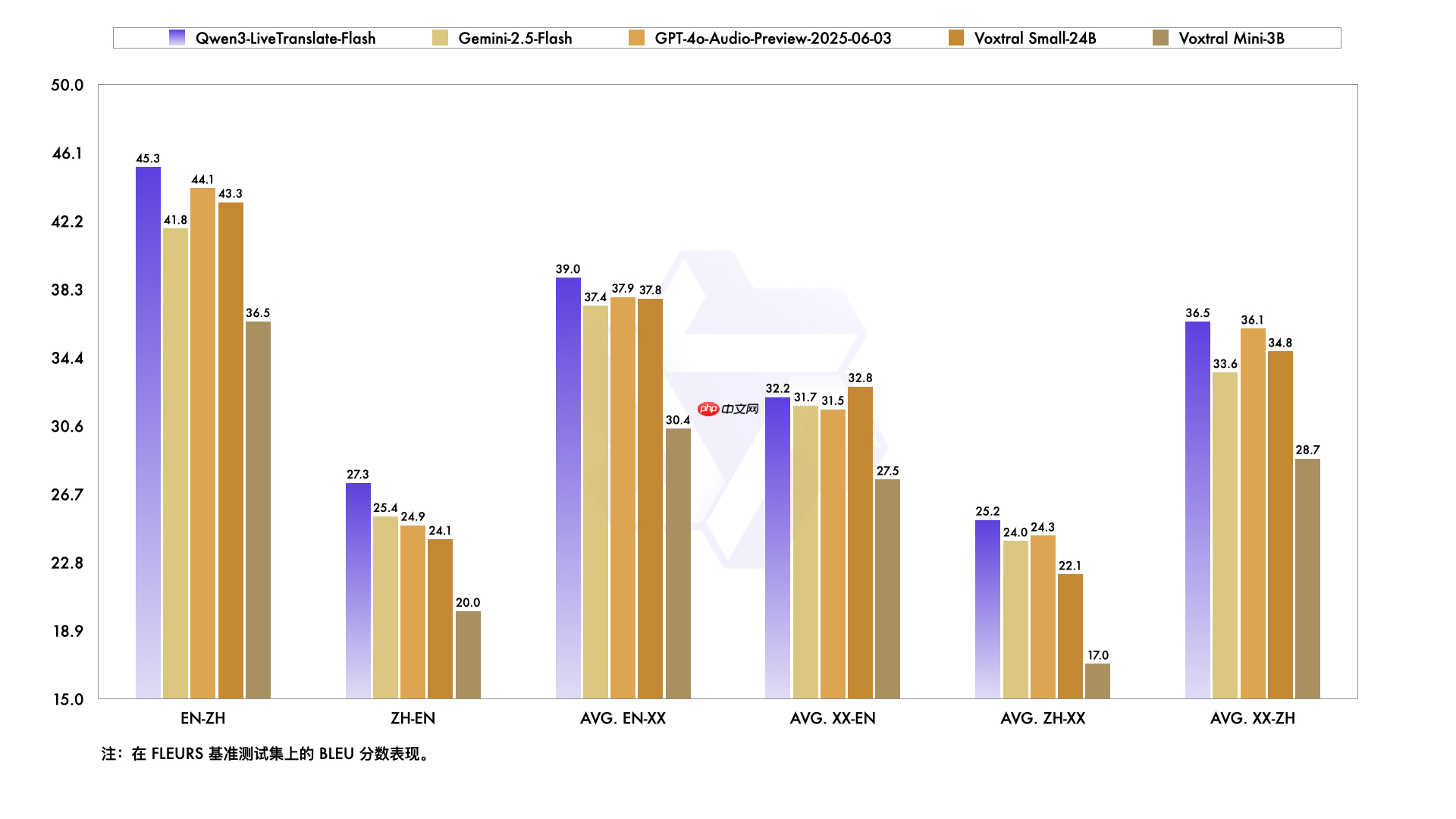
无论是在会议、访谈、教育还是影视等多样化应用场景下,Qwen3-LiveTranslate-Flash 均展现出稳定领先的翻译能力,尤其在复杂声学环境和专业领域中表现突出。
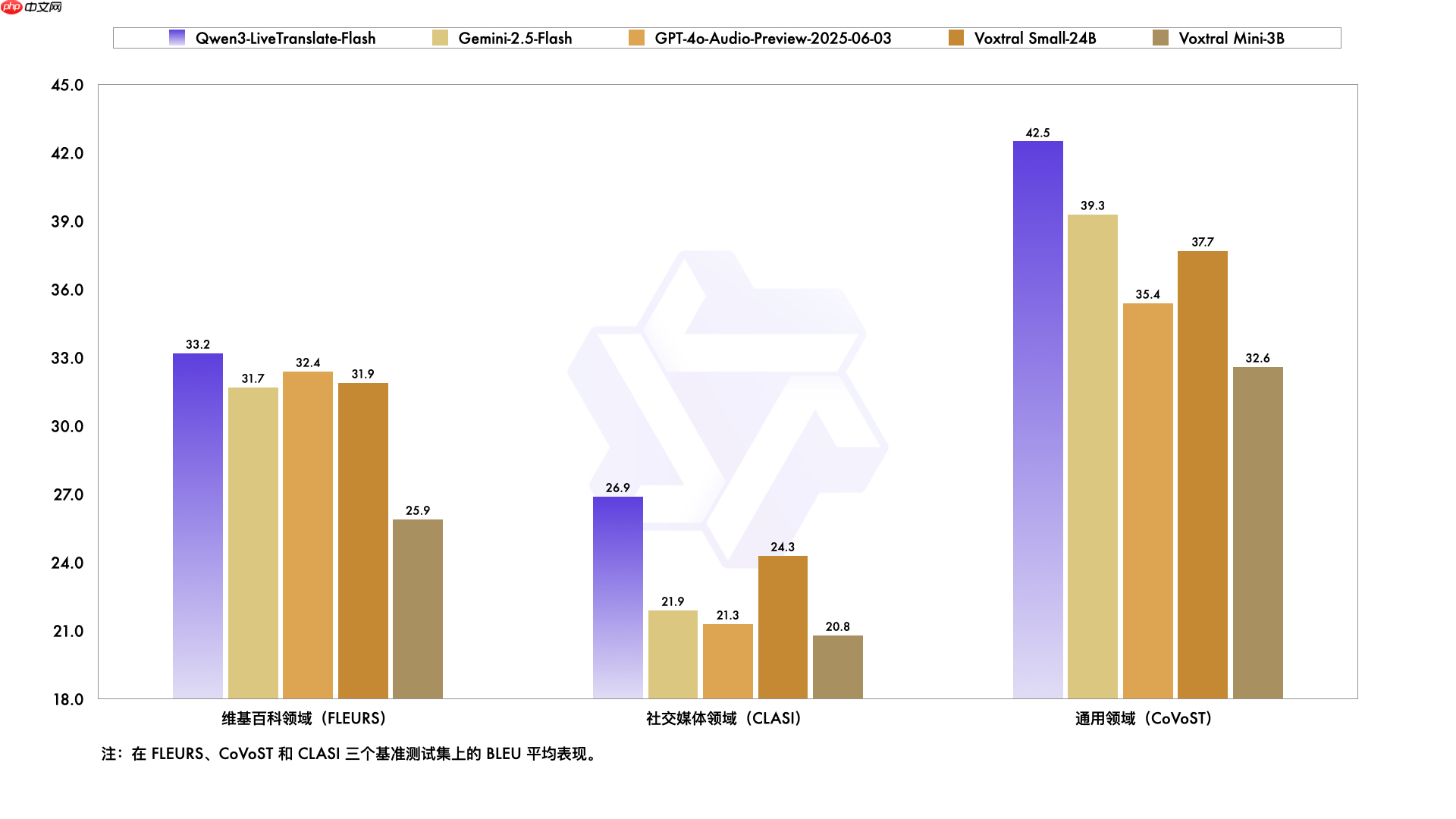
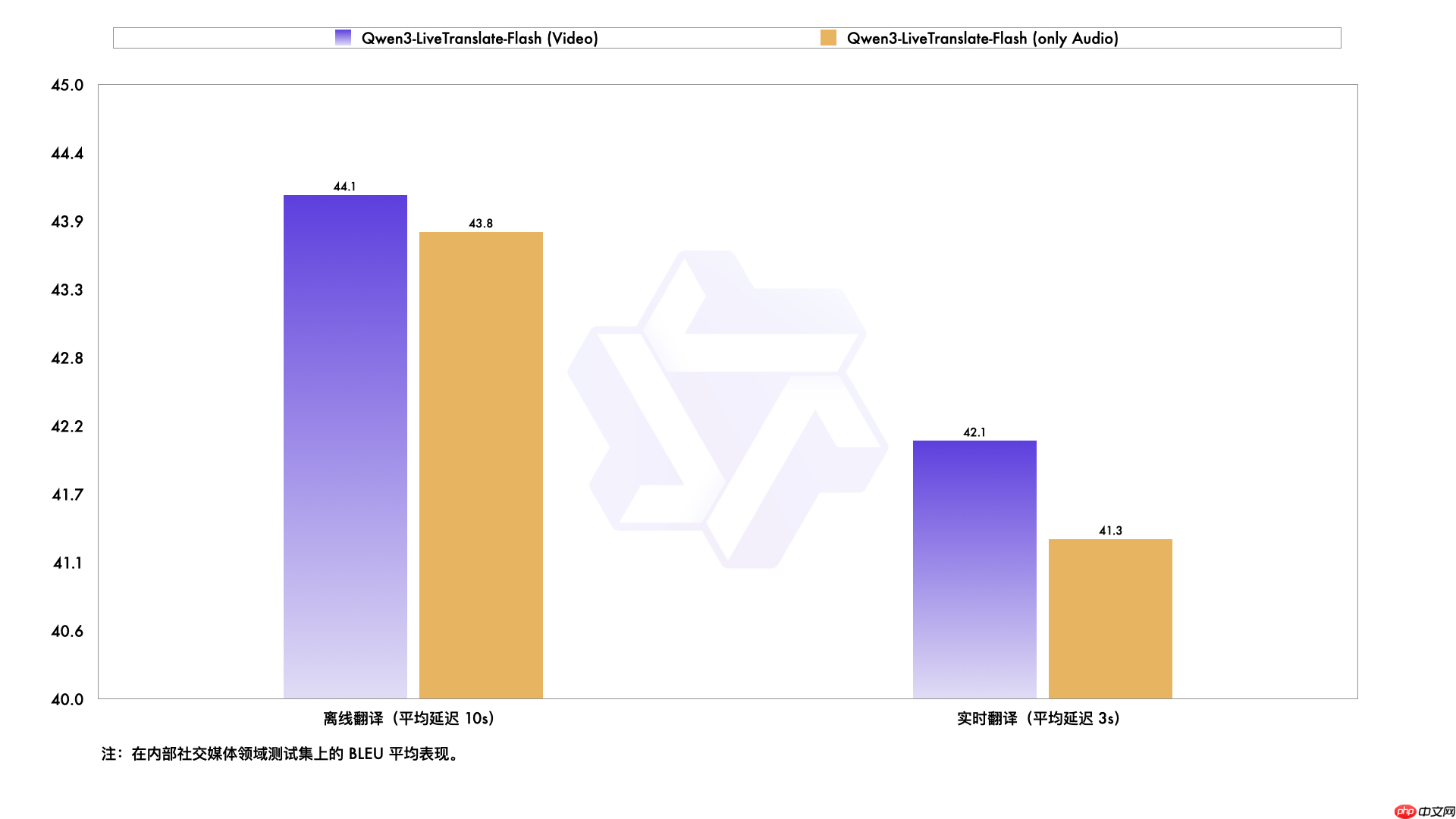
面对背景噪音、同音异义词、专有名词识别等挑战性场景,该模型凭借多模态协同理解能力实现更精准翻译。在实时模式下,视觉信息的引入显著弥补了音频断续或模糊带来的上下文缺失问题,优势尤为明显。
<< 上一篇
网友留言(0 条)